9.5 Use Case
Quevedo is one result of our project “Visualizando la SignoEscritura”1 (VisSE, “Visualizing SignWriting” in Spanish). One goal of the project was to create tools capable of automatically processing SignWriting, a graphical system for transcribing sign languages. SignWriting uses iconic symbols to represent the hands, body parts, and their movements and configurations, as the example in Figure 9.3 shows. Quevedo and its features have enabled us to create a system capable of automatically extracting the graphemes within a SignWriting transcription, assigning each of them a label representing their meaning. This required us to collect a corpus, publicly available at https://zenodo.org/record/6337885 and formatted as a Quevedo dataset. The corpus was manually and visually annotated, and a complex hierarchy of neural networks was trained on these annotations to be able to find the correct tag set for every grapheme in new instances.
For every step of this process we used Quevedo, each step guided by a few configuration lines or command line options, and the ground truth kept in the annotation files. The different steps in the process and their results can be recorded with DVC, easing experimentation and storing of measurements, as well as increasing reproducibility.
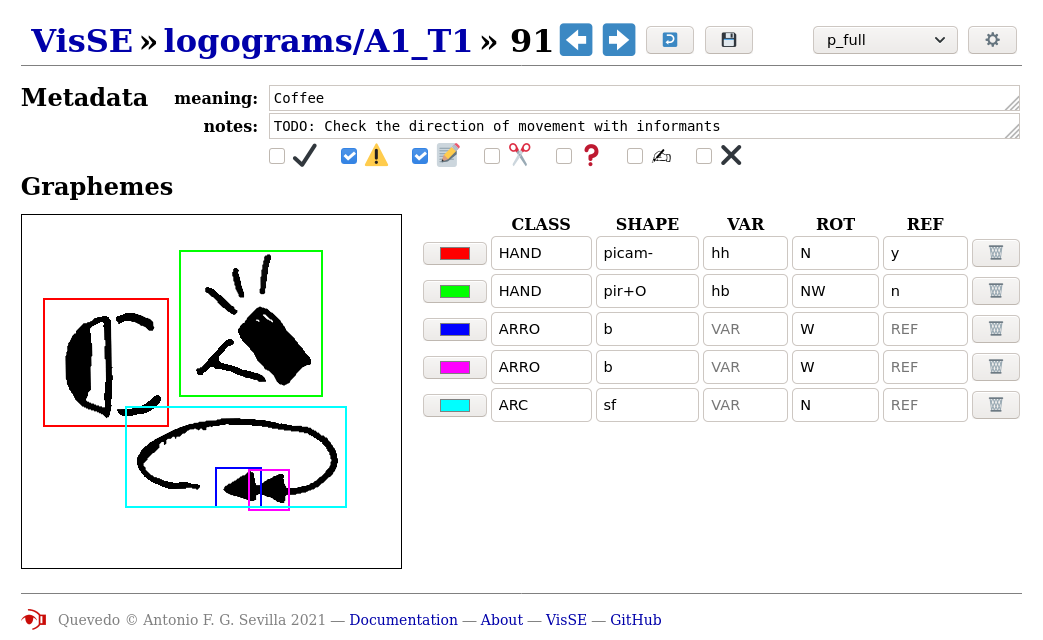
Our SignWriting data are handwritten transcriptions of Spanish Sign
Language signs, organized into sets to be able to do incremental
annotation. Metadata for each file store the annotation progress,
doubts and errors, and possible problems in the source images to take
into account. Within each logogram, the different graphemes are marked
and tagged with a set of features that captures their meaning. This
set of features, the annotation schema of the dataset, includes a
coarse-grain class for graphemes (CLASS), a fine-grain
label (SHAPE) and a possible variation
(VAR). Rotation (ROT) and reflection
(REF) are also specified, since they can alter the
meaning of the sign. The relative location of the graphemes is marked
with the bounding boxes, which are shown visually in the web
interface. An example of this annotation process can be seen in Figure
9.5.
Splitting the grapheme labels into a coarse classification (hands, head symbols, arrows, and some others) and then a finer one has allowed us to perform automatic recognition of the graphemes in steps, instead of with one single recognizer. Storing rotation and reflection of graphemes in the tags, combined with a script to “straighten” them before recognition, reduced the number of classes of graphemes to be recognized 16-fold, de-sparsifying our data and again dividing the problem of recognition into smaller steps. The trained neural networks, each specialized in a different task, were then collected into a Quevedo pipeline, making the full automatic recognition process available as a single command line invocation or a few lines of glue code.
The use of domain knowledge and deterministic rules to do part of the processing was a necessary step in our research, turning a very difficult problem into a tractable one. “Dividing and conquering” is a common strategy in computer science, and is especially necessary if the amount of data available is not as extensive as the complexity of the problem requires for a purely data-based, blind approach. Not having “Big Data” at our disposal means we can not rely on ready made, single-shot solutions to our problem, but we can still use some of the algorithms coming from the state of the art. This requires thoughtful preparation and organization of data, and building custom processing sequences. Quevedo was born to help us in doing this for our SignWriting research, but is general enough that it can be useful for other similar tasks of graphical language recognition, where data is not plentiful and requires careful annotation and processing.
For the VisSE project, the results of the data collection, annotation and machine learning were integrated into a user-facing application that explains SignWriting instances2. The application works by using Quevedo’s recognition pipeline to find the graphemes, and creating textual descriptions for each of them from the predicted tag set. While we have given a shallow overview of our SignWriting pipeline here, researchers interested in reproducing our research or extending it to new problems can find a more in-depth description in our forthcoming work “Automatic SignWriting Recognition”.
The success of the VisSE project in achieving its goals serves as an initial evaluation of Quevedo as useful software for the processing of graphical languages, as well as a demonstration of its potential for solving similar problems in the future.