8.1 Introduction
Sign Languages are a family of viso-gestual languages in use by the Deaf and Hard-of-hearing communities. Instead of sound, they rely on hand and body gestures to communicate meaning, making use of the rich possibilities of three-dimensional space and movement to build words and sentences (Barberà Altimira 2015; Brentari 2019). They are not, as it was sometimes thought by the general population, mere codings of oral language in gestures, but full natural languages with their grammar, vocabulary and evolution (Parkhurst y Parkhurst 2001; R. J. Senghas, Senghas, y Pyers 2005; Sandler et al. 2014). This recognition as actual human languages has turned them into an object of increasing interest in the research community.
Nonetheless, there is not a standard writing system in use by the signing population. The complex nature of viso-gestual communication, very different to speech, which is based on sound, makes creating or adapting a writing system not a trivial task. A number of proposals exist, most coming from the research community (Hanke 2004; Herrero Blanco 2003; Stokoe 1960). A different proposal, purported to be more user friendly, is SignWriting, which utilizes more of the graphical potential of the blank page to capture signing and its use of space in an expressive and iconic manner (Sutton y Frost 2008).
SignWriting uses abstract but recognizable symbols for the hands and other parts of the body, and then places them in 2D space to represent their relative locations in 3D signing space (Thiessen 2011). Arrows and other graphical tricks serve to fully capture the missing third and fourth dimensions (depth and time) in a system that is arguably intuitive for both signers and non-signers, making it not only a valuable recording and communication tool but also very useful for education.
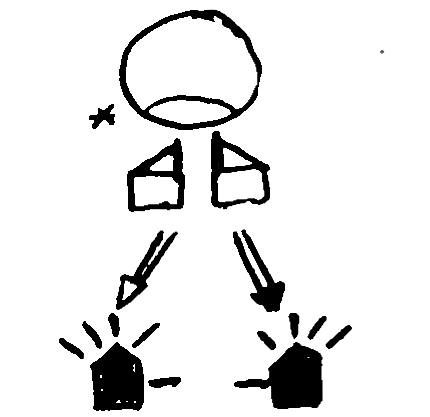
In Figure 8.1 an example SignWriting transcription is shown. This sign starts with the hands touching the chin, with the fingers flexed in a “pin” configuration. This configuration, as well as the hand orientation, are represented by the two top hand symbols. The location is signified by the circle, an iconic representation of the head, with a line marking that the chin is the actual point of contact. That there is contact at all is represented by the small asterisk to the left of the head. The hands then move downwards and to the sides, represented by the arrows, and end up fully extended and in a different orientation. In this final position, the hands are filled in black and with the fingers separated from the body of the hand to represent that the palm is facing downwards. This is just a small sample of the richness and complexity of SignWriting, but more can be read in Section 8.2 or online at https://www.signwriting.org/.
The use of graphic properties and spatial relationships makes SignWriting very different from traditional writing systems. Most writing systems in use for oral languages, if not all, are based on the sequential concatenation of characters, with only slight deviations in the co-location of diacritics and sometimes punctuation. In SignWriting, however, “characters” do not occur in a particular one-dimensional order. Instead, they appear in a complex bi-dimensional relationship, where their relative position is not arbitrary but actually represents some spatial meaning. Symbols can be rotated and reflected, and as seen before, filled in with different patterns to represent different orientations. If we count every possible graphical transformation or variation of the characters in SignWriting, there are beyond thirty thousand unique symbols to remember, understand, and be able to produce1, which again makes it very different from the “usual” writing systems.
These challenges mean that most SignWriting is produced and consumed in graphical format (i.e. images), making it difficult to process with existing language technologies or to combine with oral language resources in equal footing. Existing approaches avoid this problem by using code representations of SignWriting, like SignWriting Markup Language (Rocha Costa y Dimuro 2002; Verdu Perez et al. 2017) or Formal Signwriting (Koller, Ney, y Bowden 2013), but to be able to computationally process all the SignWriting data that exists in image form, techniques from artificial intelligence and computer vision are required.
We present in this article such a system, capable of understanding instances of SignWriting in image form by extracting a meaningful representation from the raw pixel data. This meaningful representation encodes domain knowledge of SignWriting, and we have developed an intelligent system able to automatically extract it. As far as we can ascertain from the literature, we are the first to process SignWriting images in this way.
For the processing of the graphic data in the SignWriting images, inevitably noisy and very variable, we use deep neural networks, which have very good results in pattern matching and recognition. First, we present a single state-of-the-art neural network to solve the full task, as an example one-shot approach and as baseline for comparison. Improving on the issues that this first solution presents, our proposed system further utilizes the domain knowledge encoded in our data annotation. Neural networks are arranged in a branching pipeline, with rules coming from domain knowledge used in between to reduce the complexity of the problem and make it more tractable. Later steps utilize knowledge extracted from previous steps to facilitate further processing, significantly improving accuracy compared to the naive, direct approach. This divide-and-conquer approach is possible thanks to our annotation of data into a hierarchical scheme, which lets us partition the problem into a series of sub-tasks, each easier than the full task.
One difficulty of our research lies in the sparseness and complexity of the data. There are many different symbols to learn to predict, some with different graphical variations, and some of which can be rotated or mirrored to convey different sign language meanings. These symbols are arranged in a single SignWriting transcription in a meaningful way, so it is necessary to find their relative positions at the same time as the symbol meaning is found. Combined with the small size of the available dataset, this complexity makes the search space of our problem too sparse to solve with direct application of existing neural networks. By reducing the features to extract at each step, each search space is made more dense, and entropy of the problem reduced. Not only are each of the sub-tasks then easier to solve, but the information extracted can be further processed, informing the next step and improving its results.
To recapitulate, in this article we present a novel problem for the artificial intelligence community: automatic recognition of SignWriting instances. We propose a modelization of the problem, by giving a computationally tractable description of the underlying data, and we offer a solution using some common machine learning algorithms. Due to the originality and inherent difficulty of the problem, our solution combines the machine learning algorithms with rules coming from domain knowledge. We validate our approach by evaluating its performance in solving the task, and also compare it to the performance of a direct, single algorithm, one-shot approach. These first solutions to the novel problem of SignWriting recognition validate our computational modelization of the data domain, and present an opportunity for future research to improve on the task.
The rest of the paper is structured as follows: in Section 8.2, we present an overview of Sign Language and SignWriting, to show the complexity of the problem and introduce the key points necessary to understand our system. Section 8.3 is devoted to other solutions that try to solve similar problems, and briefly presents useful deep learning approaches. Our contribution is divided into two sections: Section 8.4 discusses the underlying data engineering, and Section 8.5 presents our solution as well as the baseline approach. These are evaluated and compared in Section 8.6, and finally, Section 8.7 gives our conclusions and outlines future lines of research and development that can be followed.