6.3 Annotation Schema
The VisSE corpus is a collection of handwritten SignWriting instances (images) representing signs or parts of signs from Spanish Sign Language. These instances are annotated both graphically, by demarcating the relevant regions of the image where meaning is codified, and more conventionally using textual tags to codify the meaning and attributes of the different symbols.
6.3.1 Logograms
Each SignWriting instance is called a “logogram” (Slevinski 2016), since it represents units of meaning which are either words or word-like (not necessarily full signs1). Although the term logogram is commonly used to emphasize the non-phonetic nature of characters, it is worth noting that there are instances where sub-units may contain phonetic information (Liu et al. 2020). In the case of SignWriting, all of the sub-units are phonetic, conveying the gestures (understood in the broad articulatory sense) necessary to articulate each sign. We call each of these sub-units of writing “graphemes”.
Graphemes codify most of the phonetic content of SignWriting, and so they require the most complex annotation, consisting of not a single label but a set of features for each grapheme. The list of graphemes present, along with their feature set, is the core of each logogram’s annotation.
However, the meaning of each grapheme is not only determined by its graphical properties, but also by its position relative to the other graphemes in the logogram. It is only after contemplating both each grapheme’s features and their holistic arrangement in the page that can the sign transcribed by a logogram be understood.
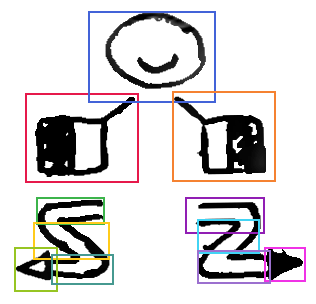
Therefore, logogram annotation consists of a list of graphemes with their relative locations, each annotated with their own independent feature set. The locations are annotated as ‘bounding boxes’, the geometrical regions within the logogram where each of the graphemes can be found. An example of this logogram annotation can be seen in Figure 6.2.
6.3.2 Graphemes
Unlike other writing systems, graphemes in SignWriting are not a one-to-one mapping from a shape or picture to a phoneme or phonemic feature, but rather encode complex meaning in their graphic form and visual properties. They have internal structure, both in their graphical properties (strokes, fill) and in their presentation (rotation, reflection). Each of these properties are encoded in a set of tags, a mapping from feature names to feature values that stores their independent meaning.
Some of this meaning is lexical, in that the shape of the grapheme must be looked up in a dictionary to understand what it represents. This is mostly the shape and outline of the grapheme’s form, which while often iconic and thus intuitive for humans to remember, is in the end conventional and abstract. The rest of the grapheme’s meaning is morphological, in that it is derived from the graphical transformation of the grapheme’s form. For example, the grapheme may be filled with different patterns of black and white, or drawn rotated around its center.
To properly annotate this meaning, a schema of five different
features or tags is used. The first two, the CLASS and
SHAPE, codify the lexical part of the grapheme’s meaning,
while the rest, namely VAR, ROT and
REF, encode the graphical transformations. As we will
see, not all graphemes can be transformed in the same way or at all,
so not all graphemes use the same set of features. Which features need
to be used is determined by the first tag, the CLASS,
which separates graphemes into different groups according to their
visual characteristics (mostly size and variability) as well as their
transformation possibilities. We have settled in six classes for our
corpus: HEAD, DIAC, HAND,
ARRO, STEM and ARC.
Once the CLASS is determined, the SHAPE
completes the lexical meaning by refining the classification down to
what a user of SignWriting might actually identify as a ‘character’.
For example, a concrete hand shape, a symbol for a head or a contact
mark. The rationale for the grouping and annotation of the different
classes, as well as any further tags needed for any of them, are
covered in the following.
HEAD and DIAC have the simplest
annotation, so are explained together in
6.3.2.1, while HAND graphemes are the most complex
and Section
6.3.2.2 is fully dedicated to them. ARRO,
STEM and ARC are grapheme classes used to
annotate the significant components of movement markers, and so are
described together in Section
6.3.2.3.
6.3.2.1 Invariant graphemes
Two first classes of graphemes are HEAD and
DIAC. These groups of graphemes do not transform, so are
always presented with the same picture, and the SHAPE
feature is enough to discern their independent meaning. They are
separated into two classes mostly due to their graphical
characteristics. HEAD graphemes are big and sparse, while
DIAC graphemes are small and compact. Nonetheless, they
also have different characteristics in how they contribute to the
meaning of a logogram.
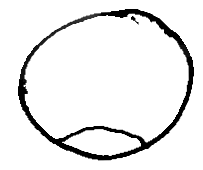


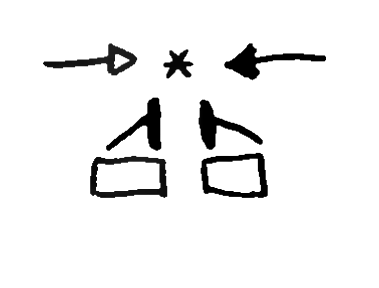
HEAD
graphemes,
representing
different
parts
of
the
head
as
place
of
articulation.
The
first
is
SHAPE=chin
;
the
second
SHAPE=mouth
,
and
the
third
SHAPE=smile
.
This
third
grapheme
represents
not
only
the
head
as
a
body
part,
but
also
the
“smiling”
facial
expression,
which
can
be
semantically
relevant
in
sign
languages.HEAD graphemes, by depicting the head or some of its
parts (eyes, nose, etc), establish a place of articulation, and the
location of other graphemes is decided relative to them. Additionally,
iconic representations of the eyes, mouth, and other elements can be
used to transcribe facial expressions, an important non-manual
parameter of sign languages. Some examples of HEAD
graphemes can be seen in Figure
6.3.
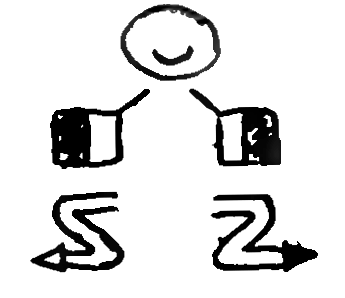
DIAC graphemes act more like diacritics, modifying the
meaning of nearby graphemes in some predictable way—hence the name,
though no profound thinking has been given to whether they actually
count as traditional diacritics. Some examples of DIAC
graphemes are dynamic marks, which establish the coordination of the
hands, or the velocity of the signing, thus affecting the whole
logogram and having a mostly arbitrary place within it. Other marks,
such as internal movements of the hand, or contact markers, must be
placed nearby the graphemes which they modify, though there are no
hard rules as to where exactly.

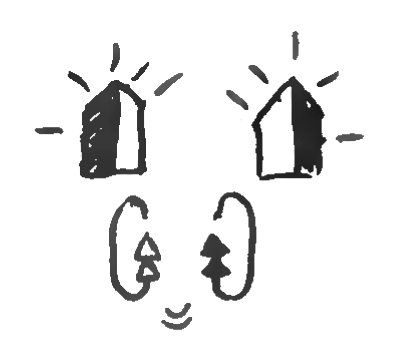
DIAC
graphemes
from
the
corpus
are
shown.
Clockwise
from
top
left,
the
SHAPE
s
are:
wiggle,
flex
hook,
touch
and
brush.
On
the
right,
the
logogram
for
the
sign
‘left-handed’
is
shown.
The
touch
grapheme
marks
that
the
hand
should
be
in
contact
with
the
head,
while
the
top
two
flex
hook
graphemes
specify
that
the
little
finger
must
bend
twice
in
the
“hooking”
manner
(they
are
above
a
HAND
grapheme,
explained
in
the
following).In Figure
6.4 some example DIAC samples can be seen, and their
use in combination with other graphemes in the logogram.
6.3.2.2 Hand graphemes
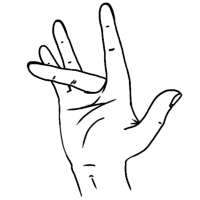
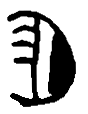
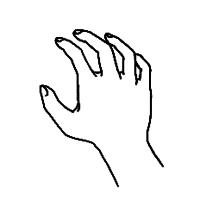
Hands are the most prominent articulators of Sign Language, and have many degrees of freedom and articulatory possibilities. Different authors assign different features to signs, but some commonalities can be found. The “hand shape” or configuration is a feature that accounts for the articulatory possibilities of the fingers, i.e. how are they bent to produce a unitary and meaningful shape; orientation is a feature specifying the rotation of the hands as 3D objects in sign space.
In SignWriting, each different hand shape is assigned a picture, a
combination of strokes that iconically represents the hand and the
fingers. This basic picture can have different filling patterns of
black and white, and can also be rotated or reflected. These different
attributes are annotated separately in our corpus, to represent their
combinatory possibilities. Hands are grouped under the
CLASS=HAND, and present the most complex annotation,
requiring all the features available in the corpus for their
annotation.
The outline of the character, which SignWriting uses to represent
the hand shape, is annotated in the tag SHAPE. This
roughly corresponds to the sign language parameter of hand
configuration, and therefore a suitable linguistic notation system can
be used to transcribe it. Some different notation systems exist for
hand shapes, varying in their applicability to different sign
languages and their ease of use. We use our own notation system,
somewhat similar to that of (Eccarius y Brentari 2008), but
specific for Spanish Sign Language. Some examples of hand shapes can
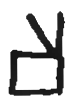
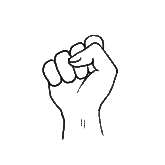
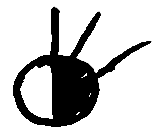
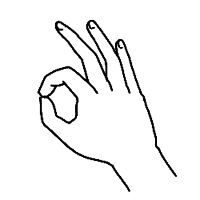
be seen in Table
6.1.
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
These basic “forms” for hand graphemes can suffer a number of
graphical alterations in SignWriting, used to transcribe the hand as a
three dimensional object in the flat page. The hand grapheme can be
filled with three different patterns: full white, full black or half
and half. Then, the grapheme can be rotated using a set of eight
possible different angles. These two transformations encode the
orientation of the hand, and are annotated in our corpus in the
VAR and ROT features.
A final graphical transformation allows the hand graphemes to be
reflected across their longitudinal axis, turning them into their
mirror image. This transformation is used by SignWriting to better
iconically depict the hand as would be seen by the signer,
representing the fingers in their correct position across the hand and
also being useful to represent left hands (which are mirror images of
the right hand). This reflection is coded in our corpus in the
REF feature, using a yes/no
value.
To decide whether a hand grapheme is reflected or not, however, is not as straightforward as it may seem. Without the wider context, it is impossible to predict whether a grapheme is an unreflected left hand or a reflected right one. For example, in Table 6.2, the fourth grapheme could be either a right or a left hand, we only know that the palm is looking left. Conversely, the fifth grapheme does not tell us, without wider context, whether it is a left or right hand, but only that the palm is oriented to the right. This wider context might be two hands, side by side, or a nearby body part, allowing humans to deduce which hand is depicted. This is inherently ambiguous, however, and requires understanding of the human body and sign language phonotactics.
|
 |
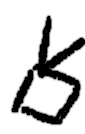 |
 |
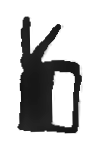 |
 |
|
|---|---|---|---|---|---|---|
VAR |
white |
white |
white |
half |
half |
black |
ROT |
North |
South |
NorthEast |
North |
North |
North |
REF |
no |
no |
yes |
no |
yes |
yes |
We choose to optimize graphical stability, meaning graphemes which
are similar in features should also be similar graphically. To this
effect we choose the half variant as the guide for
whether graphemes are reflected or not (choosing as non-reflected the
one with the palm to the left), and base the REF feature
for white or black variants on their graphical similarity to the half
one.
More examples of hand grapheme alterations can also be seen in Table 6.2. For the complete enumeration and explanation of tag values, please refer to the annotation guide that can be found in the corpus (in English and Spanish, available inside the corpus distribution file or directly at https://zenodo.org/record/6337885).
6.3.2.3 Movement marks
Hand movements are an integral part of sign language, and therefore
a substantial part of SignWriting. They are codified with paths and
arrows depicting the 3D movements of the hands in the page, describing
the shape of the movement by drawing it in an intuitive way. To
properly encode 3D space in 2D writing, they use graphical attributes
to distinguish between planes of movement, similar to how
HAND graphemes have variations to represent different
palm orientations. Some examples of movements in the corpus can be
seen in Figure
6.5.
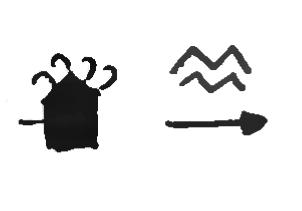
DIAC
).
Next,
top
right
(
“happy”
),
the
hands
simultaneously
do
parallel
zigzagging
downward
movements.
On
the
bottom
left
(
“together”
),
the
hands
move
from
the
sides
to
the
center
until
they
touch.
Finally,
to
the
right
(
“Sign Language”
),
the
hands
make
repeated
circular
movements
in
the
vertical
plane.What constitutes a grapheme in movement markers, however, is not an easy decision. As with other elements of SignWriting, movement symbols use both symbolic graphical properties (strokes, filling, shapes) as well as location in the page to record information. The shape of sign language movement is directly and iconically converted into bi-dimensional trajectories, with a few graphical attributes to bridge the gap to the extra dimension.
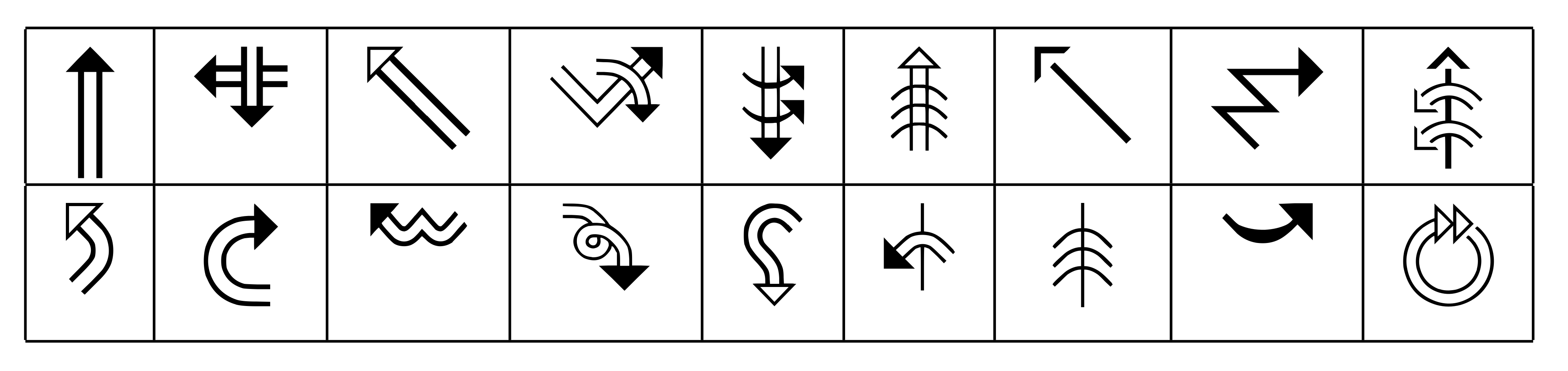
One approach would be to understand the full trajectory and associated symbols of the movement as a unit. This is the approach used by the Unicode standard and the International SignWriting Alphabet, even if some of the features, such as rotation, are encoded as different codepoints forming combining characters. Indeed, there are tens of thousands of glyphs in the International SignWriting Alphabet fonts to try and account for as many possible movements as possible, a small sample of which can be seen in Figure 6.6. Encoding movements holistically is, however, problematic for annotation due to the sheer number of them, and there is arguably a loss of information incurred when transforming a visual, meaningful, spatial representation into an index in a table (the lost information must be looked up in the table, instead of being directly available). Additionally, dealing with handwritten SignWriting renders this approach even more difficult, since it is not guaranteed that transcriptions will use only the abstractions that are collected in the Unicode representation.
Instead, we have opted to characterize the different elements of movement markers as individual graphemes. From the lexical annotation point of view, this makes sense because there are repeated elements, with identifiable semantics of their own, which can be used in different context. While these elements could be transcribed as different tags for the same grapheme, as is done for hands, their independent spatial characteristics make a subdividing approach more useful.
In Figure 6.6 we can see that arrow heads are repeating elements, as well as straight path segments, arcs and circles. Since each of them has a distinctive meaning (black arrow heads represent right hand movements, white ones left hand movements, double stemmed movements occur in the vertical plane, etc.) and there are movement marks which are distinguished only by the presence or absence of one of them, it is reasonable to think of each independent segment as individual graphemes.
Therefore, we have settled on three different classes of movement
graphemes: arrow heads ARRO, straight segments
STEM and curved segments ARC. The
SHAPE tag for each of them distinguishes between the few
different variants in the CLASS: in the case of
ARRO, the color of the arrow head marks which hands move,
and is encoded in the SHAPE. STEM and
ARC can occur in different planes of movement,
distinguished by their stems, so this is annotated in the
SHAPE. For ARCs, the SHAPE
additionally stores the amplitude of the movement, since curved
movements can be shorter or longer arcs or even full
circumferences.
Additionally to the SHAPE, all movement graphemes can
be rotated to convey orientation in 3D space. This is annotated in the
ROT tag, as is done for hands, and following the same
notation using cardinal directions2. The REF
tag is not needed thanks to subdividing movements into segments, since
each individual segment is symmetric. If movement markers were
annotated as a whole, annotating reflection would be necessary for
ARCs to distinguish clockwise and anti-clockwise
orientations, but with our approach it is not necessary (it is marked
by the orientation of the arrow head).
Some examples of this path subdivision can be seen in Figure 6.7.
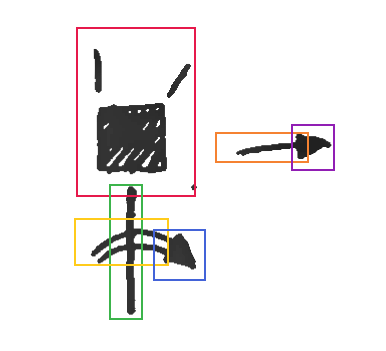
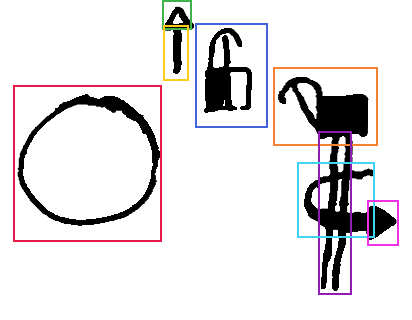
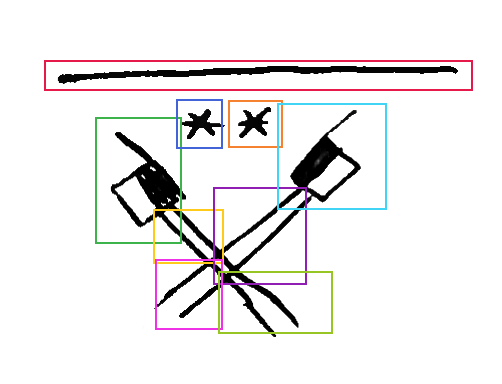
The subdivision approach also helps with marking the bounding boxes for movement graphemes. Movement paths are very graphically sparse, the actual strokes often occupying a small part of the whole rectangular region they occupy. The bounding box of the full path is not very informative either, not being able to distinguish the actual shape of the paths or their direction. This could be annotated a posteriori, but it seems a waste of effort to try to reconstruct a geometric meaning by abstract terms when the description is there, on the page, using geometric features which we can spatially annotate.
Another instance where the segmenting approach helps is with
crossings and overlapping graphemes. It is very common for movement
markers to overlap each other. Sometimes this is not a problem, for
example a small ARC crossing over a long
STEM, as is done to indicate forearm rotation. Their
geometric properties are distinct enough that spatial annotation can
be reasonably performed, their bounding boxes in a distinguishable and
characteristic arrangement even if there is much overlap (see Figure
6.7, top right). However, when there is a diagonal crossing of
STEMs, as in Figure
6.7 (bottom right), the bounding boxes overlap so much that they
become meaningless, impeding grapheme discrimination. In this case,
the paths are subdivided into consecutive sub-segments, forming a
meaningful arrangement of movement graphemes which can be annotated
and processed.
Despite the advantages we have explained, subdividing the movement
markers present one small problem. With this schema, some markers used
in SignWriting to represent body parts like shoulders, the waistline,
or forearms become indistinguishable from STEMs. Indeed,
in the case of forearms, this similarity is not a coincidence, since
they have the same features and behaviours of movement paths. They can
be double or single, depending on whether the forearm is vertical or
horizontal, and they can have overlapping ARCs to
represent forearm rotation. The only difference is that these
“STEM”s are not topped by an arrow head. Fortunately,
this is also the solution to our problem. Shoulders, forearms etc. are
annotated as STEMs, and their actual meaning is
contextual, depending on the presence or absence of actual
ARRO graphemes in their extremes. While this pushes
interpretation of graphemes’ meaning to a further layer of processing
which can take context into account, this is already a feature of
SignWriting and our annotation, so this decision maintains coherence
and makes the corpus consistent.