3.5 Software desarrollado
Como parte fundamental del desarrollo del proyecto VisSE, tanto para los esfuerzos descritos anteriormente de ciencia de datos como de algoritmia, se hizo imperativo el desarrollo de distintos tipos de software. Por un lado, se requirió software especializado para la administración de datos y la gestión de experimentos, así como para la implementación de los algoritmos de análisis y procesamiento. Por otro lado, se elaboró software de aplicación con el objetivo de brindar visibilidad y aplicabilidad práctica a los resultados obtenidos.
Retomando el objetivo complementario de esta tesis, consistente en facilitar la utilización del desarrollo realizado por terceros, opté por diseñar el software siguiendo arquitecturas estándar, e intentando abstraer los detalles concretos del dominio y corpus de datos propio. A fin de promover una mayor comprensión y aplicabilidad, se ha documentado tanto el funcionamiento como la interfaz del software, que ha sido publicado de forma abierta en la plataforma Github. Este enfoque cobra particular importancia en el caso del software de infraestructura; en lugar de recurrir a una colección de scripts ad-hoc, decidí compilar toda la funcionalidad en una librería y solución software unificada, a la que se ha denominado Quevedo.
3.5.1 Quevedo
Como hemos visto, la creación de un corpus de datos robusto constituyó uno de los esfuerzos primordiales en el desarrollo de VisSE. En este contexto, Quevedo (ver figura 3.7) emergió como un elemento crucial, habilitando una gestión eficaz del corpus mediante herramientas específicas para organizar muestras de SignoEscritura de forma estructurada.
Quevedo abarca diversas funcionalidades, que van desde la gestión de datos almacenados en disco, pasando por la administración de ficheros binarios y metadatos, hasta el procesamiento avanzado de datos. Este último incluye técnicas de “data augmentation” y el tratamiento de imágenes para la extracción de grafemas. Todos estos procesos son accesibles a través de una interfaz de línea de comandos, lo cual posibilita la incorporación de Quevedo en pipelines de datos administrados con herramientas como “Makefiles” o software especializado en ciencia de datos como DVC. Este diseño facilita la iteración y experimentación en el proceso de análisis de datos.
Un componente esencial de este corpus son sus anotaciones, las cuales, en gran medida, consisten en información visual. Quevedo brinda una interfaz web para acceder al conjunto de datos, permitiendo anotaciones intuitivas mediante acciones de clic y arrastre con el ratón. Esta interfaz no solo sirve como un medio para realizar anotaciones, sino también como una herramienta invaluable para la visualización y divulgación de los resultados del corpus. Al usar tecnología web, dicha interfaz puede compartirse con facilidad entre múltiples colaboradores, sin la necesidad de que descarguen el conjunto de datos ni instalen software adicional.
Cabe destacar que las capacidades de anotación en Quevedo son más sofisticadas que las ofrecidas por otras herramientas similares. Mientras que otras aplicaciones se limitan a permitir la asignación de etiquetas individuales a objetos, Quevedo admite un esquema multi-etiqueta, como el que se requirió para VisSE. Además, se encuentra en desarrollo una extensión que permite añadir información sintáctica, como las relaciones entre grafemas, abriendo así nuevas vías para futuras investigaciones.

Quevedo no solo resultó útil para la gestión y análisis de datos, sino que también desempeñó un papel relevante en el ámbito de la inteligencia artificial. Quevedo permite la incorporación de parametrizaciones para redes neuronales profundas como parte del conjunto de datos. Dichas parametrizaciones, definidas por el usuario en el lenguaje de configuración TOML, abarcan desde el tipo de tarea (ya sea detección o clasificación de grafemas) hasta las etiquetas y subconjuntos de datos que se emplearán para entrenar y evaluar las redes.
Este diseño posibilita la realización de experimentos de manera reproducible y transparente, manteniendo el control sobre los datos y los hiperparámetros utilizados. Asimismo, gestiona eficientemente las distintas fases del proceso de entrenamiento y evaluación de las redes neuronales. Quevedo también permite que las redes sean incorporadas en un pipeline dinámico, junto con procesos deterministas, facilitando la implementación y la iteración de la solución diseñada en el esfuerzo de IA.
En resumen, al encapsular las diversas fases de la investigación en el software Quevedo, se logró simplificar de manera significativa la exploración y experimentación iterativas. Este enfoque fortalece además la trazabilidad y reproducibilidad de los experimentos, ayudando a cumplir con nuestro objetivo complementario de difusión y utilidad para la comunidad científica.
A continuación haremos una breve descripción del diseño arquitectónico de la librería, pero para mayor detalle se puede consultar la documentación (capítulo 10) o directamente el código fuente en https://github.com/agarsev/quevedo.
3.5.1.1 Arquitectura de Quevedo
Quevedo está diseñado como una librería, programada en Python, que ofrece las distintas funcionalidades, así como una interfaz de comandos para acceder a las mismas. Utiliza la librería ‘Click’ para la creación de la interfaz de comandos, ‘Pillow’ para el procesamiento de imagen, y ‘Flask’ para la construcción de la interfaz web. La parte dinámica de dicha interfaz web se ha desarrollado en JavaScript, haciendo uso de ‘preact’. Las redes neuronales se gestionan con el software ‘Darknet’, desarrollado por el propio inventor del algoritmo YOLO.
El elemento central de Quevedo es el objeto denominado “Dataset”, que representa un conjunto de datos almacenados en el disco duro. Este objeto permite al usuario acceder y manipular anotaciones sin la necesidad de gestionar archivos de forma manual. El objeto “anotación” (Annotation), que puede constituir un grafema o un logograma, se obtiene a través de las funciones de búsqueda que ofrece el dataset. Este objeto otorga acceso a metadatos, anotaciones y datos de imagen, permitiendo su modificación si se considera necesario. Adicionalmente, el objeto Dataset ofrece acceso a las redes neuronales incluidas en el conjunto de datos, las cuales pueden ser empleadas tanto para inferencia como para entrenamiento.
Dado que Quevedo está diseñado como librería, sus funcionalidades pueden ser incorporadas en otros programas. Esto posibilita la construcción de software que se erige sobre los resultados obtenidos con Quevedo, facilitando así el desarrollo de aplicaciones de usuario como la que se describirá más adelante.
Otra característica importante de Quevedo es su naturaleza agnóstica de dominio. En su codificación, intenté separar lo máximo posible los detalles correspondientes a la SignoEscritura y las funcionalidades más genéricas y abstractas. Esto otorga a Quevedo una versatilidad que trasciende su aplicación original; es decir, la herramienta puede ser útil en otros dominios en los cuales sea necesario identificar y clasificar componentes con significado independiente pero sintácticamente relacionado dentro de imágenes con un significado composicional.
Si bien esta utilidad podría considerarse altamente especializada a primera vista, lo cierto es que hay una variedad de “lenguajes gráficos” que podrían beneficiarse de su arquitectura. Ejemplos de esto son la aritmética elemental, los diagramas UML (Lenguaje Unificado de Modelado, por sus siglas en inglés), o los diagramas de Feynman. Sin embargo, la adaptación de Quevedo para estos otros dominios representa una línea de investigación futura.
Para más información sobre Quevedo, se puede consultar el capítulo 9, la publicación científica donde describimos el software, o directamente la documentación técnica, publicada en línea e incluida en este documento también en el capítulo 10. Una demostración que incluye el corpus de VisSE se halla disponible en la dirección https://holstein.fdi.ucm.es/visse/quevedo/2.
3.5.2 Aplicación web
Uno de los aspectos destacados de la investigación en lingüística es su cercanía con la sociedad. Dado que todos empleamos el lenguaje en nuestra vida diaria, resulta sencillo encontrar nexos entre la investigación académica y el público en general.
En lo referente a las lenguas de signos, este vínculo con la comunidad de personas sordas y signantes es sumamente potente y palpable. Todos los esfuerzos emprendidos en la investigación y el desarrollo de las lenguas de signos conllevan a un mayor reconocimiento, expansión y aceptación de las mismas, razón por la cual la comunidad signante acoge con entusiasmo cualquier forma de participación.
Sin embargo, la lingüística computacional presenta ciertos desafíos, principalmente debido a la necesidad de dispositivos específicos y a menudo, requisitos de software que no resultan fácilmente accesibles. En nuestro caso, el empleo de algoritmos avanzados de aprendizaje automático representa una dificultad considerable. El obstáculo no reside únicamente en el hecho de que no podemos solicitar a los usuarios que ejecuten nuestros algoritmos, sino que comúnmente ni siquiera poseen el hardware requerido.
Afortunadamente, los avances recientes en tecnología web y en los navegadores de internet posibilitan el uso de arquitecturas cliente-servidor que eluden estos inconvenientes. Los navegadores web modernos constituyen entornos de ejecución potentes que incluyen interfaces de usuario, acceso a recursos del dispositivo y una capacidad de cómputo significativa. Pero, lo más relevante, es que todo ello se logra mediante estándares ampliamente aceptados y una arquitectura subyacente distribuida. Si se evita la utilización de tecnologías de vanguardia, se garantiza un entorno de ejecución, el navegador, compatible con casi todos los dispositivos que el usuario pueda tener: ordenadores de sobremesa, dispositivos móviles, tabletas e incluso consolas de videojuegos.
Adicionalmente, el navegador se encuentra conectado de forma nativa a la red, lo que nos permite ejecutar en el servidor las partes de la aplicación que requieren hardware y configuración específicos, delegando el resto de las tareas al dispositivo cliente.
Por consiguiente, como culminación del proyecto VisSE, y con el objetivo de brindar un acceso sencillo y accesible a los resultados de nuestra investigación, desarrollé una aplicación web progresiva (progressive web app, PWA) que está disponible en la URL https://garciasevilla.com/visse.
3.5.2.1 Explorador didáctico de SignoEscritura
Para crear una aplicación final que culmine nuestro desarrollo de reconocimiento de SignoEscritura, necesitamos plantearnos cuál es la funcionalidad que puede resultar útil a un usuario general, no científico. Desafortunadamente, nuestro desarrollo no ha alcanzado el nivel de poder realizar una traducción automática, que sería el objetivo último de este tipo de investigación. Tampoco existen recursos de LSE con los cuales conectar de manera sencilla, que pudieran servirnos para enlazar la SignoEscritura reconocida a un diccionario o similar. No obstante, estamos trabajando en ello en el proyecto Signario3, ya mencionado anteriormente (Lahoz-Bengoechea y Sevilla 2022a), y con un poco de suerte en el futuro próximo se pueda ampliar esta funcionalidad.
Lo que sí podemos hacer con el trabajo realizado, y que resulte
útil para un usuario final, es tomar el conocimiento implícito en
nuestra algoritmia de reconocimiento y convertirlo en conocimiento
explícito y accesible para el usuario. Esto es, transformar los
grafemas detectados, junto con sus parámetros (CLASS,
SHAPE, etc.), en explicaciones en español, y utilizarlos
para ayudar a personas que no conozcan la SignoEscritura. Por ejemplo,
esto puede ser útil para estudiantes de LSE, usuarios de un
diccionario escrito en SignoEscritura, o para los propios signantes
que, a pesar de su conocimiento nativo de la lengua, no conozcan la
SignoEscritura y por lo tanto no dispongan de un sistema de escritura
efectivo. A través de nuestra aplicación, pueden ver el significado
“fonético” de los logogramas y grafemas desconocidos, reproduciendo
las configuraciones y gestos física o mentalmente, y reconocer con
ello qué signo o elemento gramatical está codificado en la imagen.
La aplicación se compone de dos partes principales. En primer lugar, el cliente, que se ejecuta en el dispositivo del usuario. Está programado con el paradigma de interfaz de usuario (UI) “reactiva”, uno de los más extendidos en la actualidad en la programación web. El software por excelencia de este paradigma es React, una librería JavaScript creada por los ingenieros de Meta (anteriormente Facebook), y que llevo utilizando desde la versión 0.14 (Sevilla 2015). Para la aplicación de VisSE, empleamos una versión más ligera de React conocida como Preact. El estilo visual está diseñado con Tailwind CSS, una librería de estilos moderna que encaja muy bien en el paradigma y en la forma de desarrollo de las PWAs.
La aplicación del cliente se comunica con el servidor (backend), creado utilizando FastAPI. FastAPI es una librería Python destinada a la creación eficiente de servidores con APIs, manteniendo al mismo tiempo un alto nivel de buenas prácticas y una alta compatibilidad mediante el uso de estándares extendidos. La función de FastAPI es principalmente de mediador, y la mayor parte del trabajo del backend recae en la propia librería Quevedo. FastAPI recoge las peticiones del usuario, las procesa con la funcionalidad de Quevedo y envía la respuesta al frontend en formato JSON.
Para implementar esto, incorporamos al backend un sistema de generación de lenguaje natural que crea explicaciones, empleando plantillas para convertir el conocimiento codificado en las etiquetas de los grafemas en explicaciones accesibles al gran público.
El frontend, por su parte, permite al usuario seleccionar o capturar una imagen de SignoEscritura, que es enviada al servidor. Para poder demostrar la aplicación a usuarios que no dispongan de muestras de SignoEscritura, el frontend proporcionan también algunos ejemplos sin necesidad de que el usuario busque o dibuje ningún logograma. Una vez recibida la imagen elegida, el backend utiliza la funcionalidad de Quevedo para ejecutar el pipeline de reconocimiento entrenado con el corpus VisSE y descrito en secciones anteriores. El resultado es, como hemos visto, una lista de los grafemas detectados, junto con sus atributos portadores de significado. El backend convierte este resultado en texto natural, y lo envía de vuelta al frontend, junto con algunos metadatos adicionales.
El frontend recoge esta respuesta y la muestra al usuario en una interfaz adaptada al tamaño de pantalla disponible, como se puede apreciar en la figura 3.8. El usuario puede navegar por las explicaciones, observando a qué grafema corresponden, o hacer clic directamente en los grafemas para ver qué significa cada uno.
3.5.2.2 Modelo 3D de la Mano
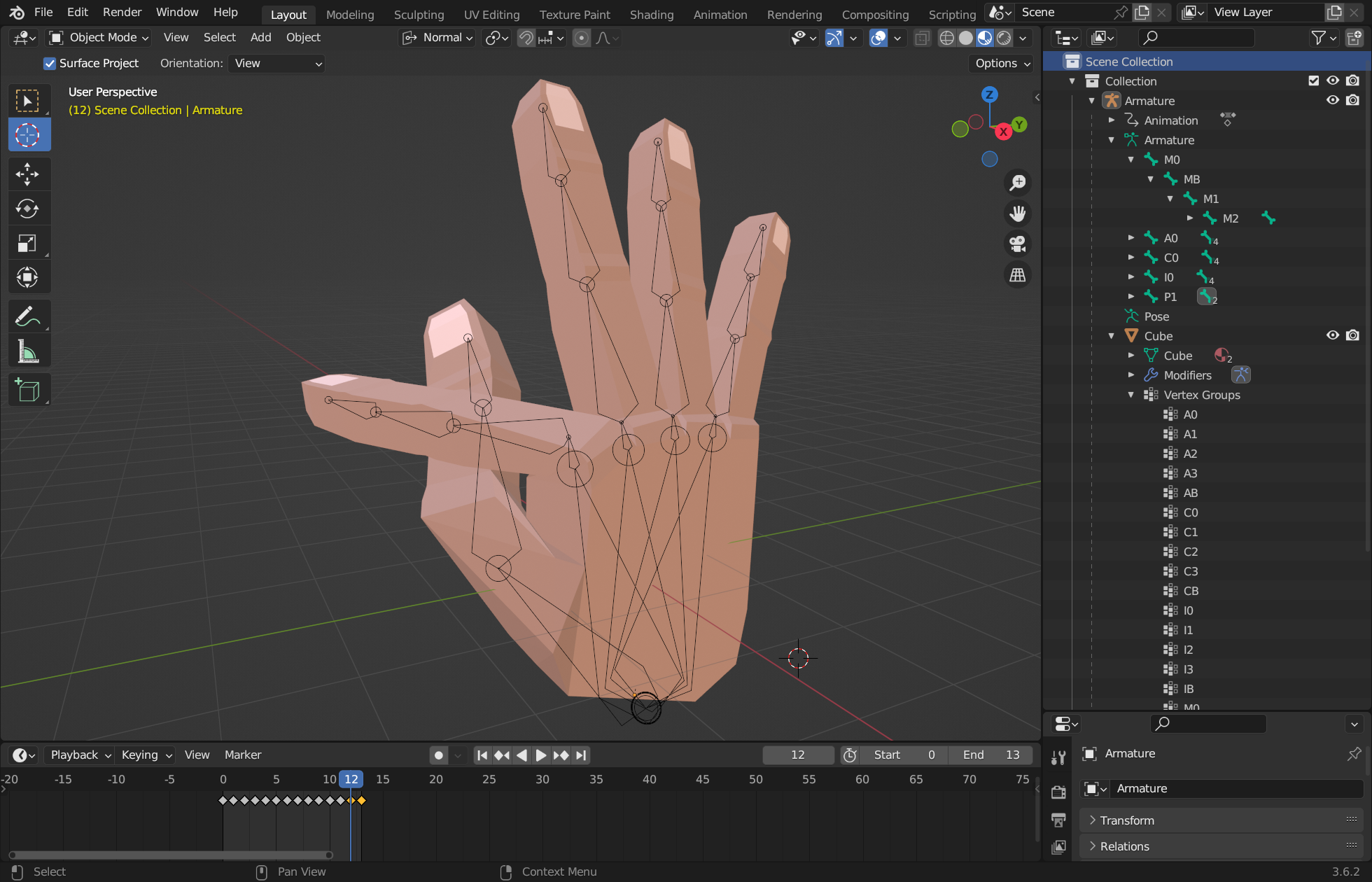
Adicionalmente, en lo que respecta a los grafemas manuales, se proporciona un modelo tridimensional interactivo que puede facilitar la comprensión de la posición de los dedos y la orientación de la mano, sirviendo de complemento a la descripción textual.
Este modelo tridimensional, creado personalmente utilizando la herramienta Blender4, emplea el conocimiento fonológico adquirido a lo largo de estos años de investigación. La intención original residía en la creación de un avatar 3D completo, capaz de reproducir todos los rasgos de la LSE, pero este objetivo resultó ser excesivamente ambicioso, por lo que se optó por una aproximación más limitada.
No obstante, el modelo de la mano es considerablemente completo y captura con precisión la fonología configuracional de la mano en la LSE, de acuerdo con nuestra teoría actual. Dicho modelo ha sido publicado en acceso abierto bajo una licencia de código abierto, lo cual permite su utilización por otros investigadores o en diferentes aplicaciones. Ejemplos de estas aplicaciones, desarrollados durante la tesis, se pueden encontrar en la sección A.3, aunque utilizando un modelo 3D de una versión anterior.
En términos técnicos, el código del modelo se ha implementado en JavaScript, aprovechando la librería THREE.js. De esta manera, su uso no requiere de la instalación de ningún software específico, más allá del navegador, permitiendo su utilización en la mayoría de ordenadores y dispositivos móviles ampliamente difundidos.
Este modelo 3D (figura 3.9), así como la funcionalidad fonológica implementada, es otro resultado de desarrollo software dentro del proyecto VisSE, quizá secundario ante la funcionalidad de reconocimiento de SignoEscritura pero que también abre la vía a futuros desarrollos y aplicaciones.