3.3 Diseño del corpus y esquema de anotación
El primer esfuerzo del proyecto, enmarcado en la “ciencia de datos”, consistió en la recolección, tratamiento y anotación de un corpus de datos sobre el cual basar el procesamiento posterior. Teníamos disponible una gran cantidad de vocabulario de la Lengua de Signos Española (LSE), adquirido durante las clases en el Centro de Idiomas Complutense, y registrado en forma de SignoEscritura1 escrita a mano sobre papel. Para convertirlo en “datos” utilizables, sin embargo, era necesario un proceso previo. Las distintas hojas de papel debían ser escaneadas, procesadas para mejorar el contraste y eliminar artefactos y ruido, y los distintos logogramas debían ser extraídos como muestras individuales. Afortunadamente, gracias al proyecto, pudimos ofrecer una gratificación a un colaborador externo para que realizara la mayoría de la parte mecánica del proceso. También recopilamos una serie de grafemas de manos, dibujados por el equipo investigador del proyecto en varias modalidades. Estos grafemas de manos finalmente no fueron utilizados para el proyecto, pero están disponibles en el corpus para aumentar la diversidad y exhaustividad de los datos.
Una vez recogidas todas las muestras “crudas”, las imágenes escaneadas de los logogramas, fue necesario anotarlas para capturar su estructura y significado de manera computacional. La anotación de datos es un proceso tan importante y delicado como su correcta digitalización, ya que los modelos computacionales solo podrán trabajar con el conocimiento que haya sido adecuadamente capturado. De nada le sirve a un ordenador que los humanos sepamos cosas sobre un dominio de conocimiento, si esa información no está representada de manera lógica y formal. A menudo los humanos no somos conscientes de la cantidad de conocimiento que asumimos de manera implícita, incluso en áreas del conocimiento tan estrictas como la ciencia o la ingeniería.
En el pasado he trabajado en el dominio médico, y sorprende tanto a los informáticos como a los propios médicos la cantidad de hipótesis, suposiciones y “sentido común” que no son explícitos y, sin embargo, subyacen al proceso formal. Es además fundamental que los datos estén anotados de forma precisa y correcta, ya que los errores se van acumulando con cada paso de procesado o capa de abstracción, hasta llegar en ocasiones a modelos teóricos completamente incorrectos por basarse en datos pobremente anotados (Sambasivan et al. 2021).
En el caso del PLN o la LC, el problema del conocimiento implícito se multiplica. Cuando decimos “gato”, a nosotros ya nos vale como representación última de la información; o si somos biólogos, quizá preferimos decir Felis domesticus, y añadir algunas precisiones más. Como humanos, compartimos una realidad en la que existen los gatos, por lo que compartimos ese concepto en nuestra mente, y con crear un signo (la palabra) para el significado, hemos terminado. El ordenador, al ser una máquina puramente lógica y no tener el contexto o la experiencia humana, necesita que todo el conocimiento que se quiera utilizar esté explícitamente codificado.
Este fenómeno se puede observar también con la SignoEscritura, ya que a pesar de estar formalmente definida en términos humanos, el formalismo no es suficientemente detallado para su procesamiento automático. La SignoEscritura asume, por ejemplo, que el humano será capaz de trasladar el espacio bidimensional al espacio 3D de manera intuitiva, o entender qué manos son derechas y cuáles son izquierdas. Era por tanto necesario desarrollar un modelo de la SignoEscritura computacionalmente adecuado y que además permitiera el procesamiento que teníamos en mente. Afortunadamente, llevábamos ya varios años investigando sobre la fonética y fonología de la LSE, y pudimos aprovechar nuestro conocimiento e hipótesis sobre ellas para desarrollar el modelo de representación para la SignoEscritura. Además, gracias a mi investigación inicial sobre el reconocimiento automático de lengua de signos, también tenía claro los requisitos de la anotación para que fueran aprovechables por los algoritmos de visión artificial. El resultado fue un modelo de anotación exhaustivo y estructurado, que sirve para capturar tanto las propiedades físicas de la SignoEscritura como el significado de los distintos grafemas y sus propiedades. Este esquema de anotación es clave para el éxito del resto del proyecto, y representa bien la convergencia de análisis teórico y conocimiento experto con técnicas informáticas y de aprendizaje automático que es la metodología resultado de esta tesis.
La primera clave de esta representación radica en la definición de los términos logograma y grafema, asignando las propiedades léxicas y morfológicas a los grafemas, y concebiendo el logograma como una composición sintáctica de los mismos. Para los grafemas, se definió un conjunto de cinco etiquetas. La primera, denominada “clase”, representa una clasificación de grano grueso que tiene por objetivo dividir a los grafemas en grupos con características tanto gráficas como semánticas afines. Esta clasificación es fundamental para el procesamiento posterior y, además, está justificada lingüísticamente, pudiendo ser interpretada como un análogo de la parte de la oración (“Part of speech”, POS). La segunda etiqueta, denominada “forma” (shape), determina el grafema propiamente dicho tal y como sería comprendido por los seres humanos. Esto incluye cada una de las manos, cada uno de los símbolos de cabeza, las partes de los movimientos, etc. Estas formas están implícitas en la SignoEscritura y en los materiales didácticos, pero no están clasificadas de una manera sistemática ni con una nomenclatura significativa. En la representación digital existente de la SignoEscritura, denominada “Formal SignWriting” (FSW, Slevinski 2016), los grafemas se identifican mediante un número, su código de carácter Unicode, pero estos números son poco prácticos, ya que es difícil para un humano memorizarlos todos, y además, no proporcionan información sobre el significado (fonético) del grafema que representan.
Por tanto, fue necesario desarrollar una nomenclatura sistemática para la forma de los grafemas. De particular interés es la nomenclatura utilizada para las manos. Existen más de 60 configuraciones de la mano en la LSE, que no corresponden a letras ni palabras del español, por lo que su representación no es trivial. Para clasificarlas, recurrimos a nuestro sistema, la Signotación (Lahoz-Bengoechea y Sevilla 2022b), mencionada anteriormente y que codifica las distintas configuraciones con caracteres ASCII. Esta notación se basa en nuestra investigación de la fonología de la LSE, y su uso en el corpus demuestra su utilidad tanto para una descripción lingüísticamente correcta y exhaustiva de la LSE como para su procesamiento automático.
Además de la clase y la forma, que conjuntamente conforman la clasificación de los grafemas, estos tienen propiedades gráficas que también requieren anotación. Los grafemas pueden aparecer rotados, reflejados, y presentar distintos colores y rellenos. Aunque los seres humanos, gracias a nuestra percepción visual, somos capaces de reconocer estas transformaciones y entender que la forma del grafema es la misma, en la imagen tal como es interpretada por el ordenador, son completamente distintas. En la FSW y las fuentes tipográficas digitales de SignoEscritura, se asignan números distintos a cada una de estas variaciones, incrementando así la cantidad total de símbolos. Aunque estos números están asignados de manera consecutiva y con cierta lógica, terminan siendo meramente un índice, que no ofrece información sobre las propiedades gráficas (la transformación) del grafema.
Como dato curioso, en la versión oficial de Unicode para SignoEscritura (The Unicode Consortium 2021, 831-32), en lugar de esta explosión combinatoria, se designan secuencias de caracteres o clústeres de grafemas, en los que el primer carácter representa la forma, el segundo una variación tipográfica, el tercero la rotación, etc. Sin embargo, esta representación, que es análoga a la nuestra (desarrollada de forma independiente) y más o menos compatible, no parece estar en uso en FSW ni en ninguna otra herramienta oficial de SignoEscritura, probablemente debido a la complejidad de su uso sin herramientas especializadas.
En nuestra anotación sistemática, la información gráfica tal como la variación (color, relleno), la rotación y la reflexión (espejo) de los grafemas constituyen el resto de etiquetas que completan la información atómica proporcionada por cada grafema. Sin embargo, aún falta la información sintáctica, es decir, la manera en la que los grafemas se combinan dentro del logograma. A diferencia del lenguaje oral, que es lineal y unidimensional y donde las palabras ocupan una posición ordenada en la oración, en la SignoEscritura los grafemas se disponen de manera dispersa en un plano bidimensional. Resulta necesario, por tanto, anotar la ubicación de los grafemas, para lo cual almacenamos el centro de cada uno de ellos, con coordenadas \((x, y)\). Para evitar distorsiones artificales por el tamaño de cada logograma, en lugar de la posición en píxeles empleamos una fracción que varía de 0 a 1, indicando la posición del grafema relativa al “lienzo” del logograma.
Sin embargo, grabar únicamente la posición con dos coordenadas no es suficiente, ya que no se puede ignorar el tamaño de los grafemas. Aunque no sea explícitamente significativo, y pueda haber variación en la escritura de distintas personas, es indispensable que el ordenador conozca este aspecto para realizar el reconocimiento automático, ya que es necesario delimitar físicamente el área de cada grafema. Además, el tamaño es sintácticamente relevante, puesto que muchas construcciones en SignoEscritura se basan en la cercanía de los grafemas. Esta cercanía, sin embargo, no es la distancia entre sus centros, calculable con las posiciones puntuales, sino la distancia entre sus bordes, y para calcularla se necesita conocer extensión gráfica de los grafemas. Por lo tanto, almacenamos otro par de coordenadas, el ancho y alto del grafema (de nuevo relativos al tamaño del logograma). Es decir, en total, para cada grafema anotamos su la información “léxica” (clase y forma) y “morfológica” (relleno, rotación, reflexión), pero también su posición y tamaño como atributos numéricos adicionales.
Para una exposición completa sobre la anotación, incluyendo los distintos valores de las etiquetas, se recomienda consultar la guía de anotación del corpus, disponible en inglés en el capítulo 7 y en español junto a los datos publicados en línea2. Se puede ver un ejemplo también en la figura 3.4. Este esquema de anotación del corpus VisSE es una de las innovaciones de esta tesis, ya que captura una información para cada muestra más sofisticada que la habitual en el campo de la visión artificial, y está además lingüísticamente motivada, habilitando el uso efectivo de los datos para las aplicaciones posteriores.
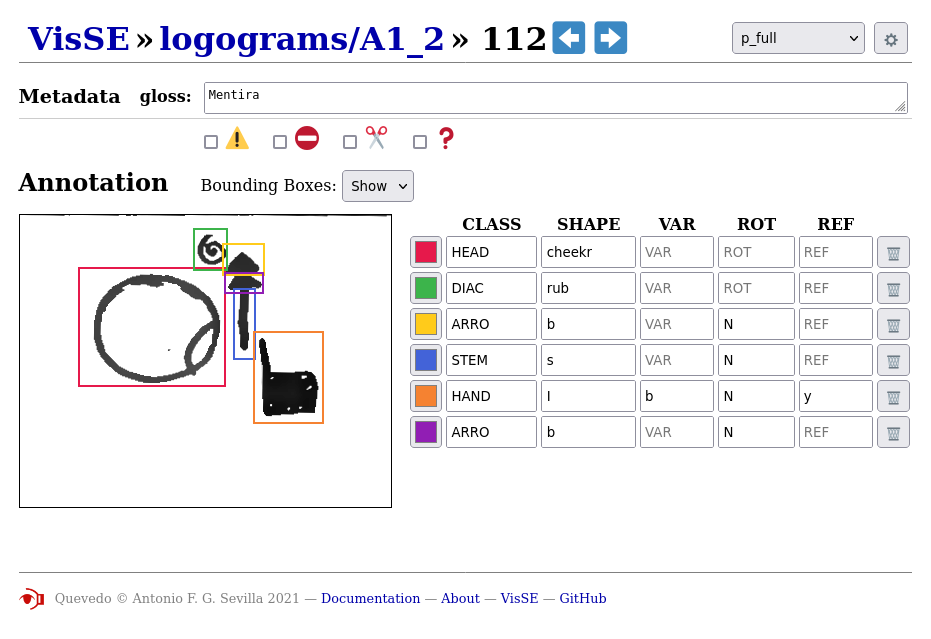
Es preciso señalar que, además de definir el esquema de anotación, también es necesario realizar la anotación en sí, es decir, el proceso manual de identificar cada grafema presente en un logograma y asignar los valores para sus respectivas etiquetas. A pesar de ser una labor ardua, meticulosa y mecánica, requiere un conocimiento profundo de la anotación y del dominio, por lo que su externalización no es tarea sencilla. El proceso de anotación tampoco es directo, ya que, a medida que se anotan más datos y se realizan experimentos, se identifican problemas y mejoras en el esquema de anotación, lo que exige revisar las anotaciones previamente efectuadas. Este proceso consume una gran cantidad de tiempo, y resultó en la anotación de 982 logogramas. Esta cifra es significativa y fue útil para el resto del proyecto, pero representa menos del 40% de las muestras recogidas.
Un ejemplo de este proceso de revisión se puede ver con la aparición de los signos “bimorfémicos”. En el vocabulario original recogido, la mayoría de los signos estaban transcritos con un solo logograma. Sin embargo, algunos signos presentaban dos “partes”, comúnmente denominadas sílabas en la literatura, aunque en nuestro estudio las consideramos más próximas a los morfemas. En cualquier caso, cada una de estas partes constituye un logograma independiente, situación que generaba numerosos problemas durante el reconocimiento automático. Optamos por dividirlos en dos, pero ello implicaba repetir la anotación para muchos signos. Afortunadamente, la herramienta informática que habíamos desarrollado para crear y gestionar el corpus (Quevedo) nos facilitó llevar a cabo esta tarea de manera más o menos automatizada (ver figura 3.5).
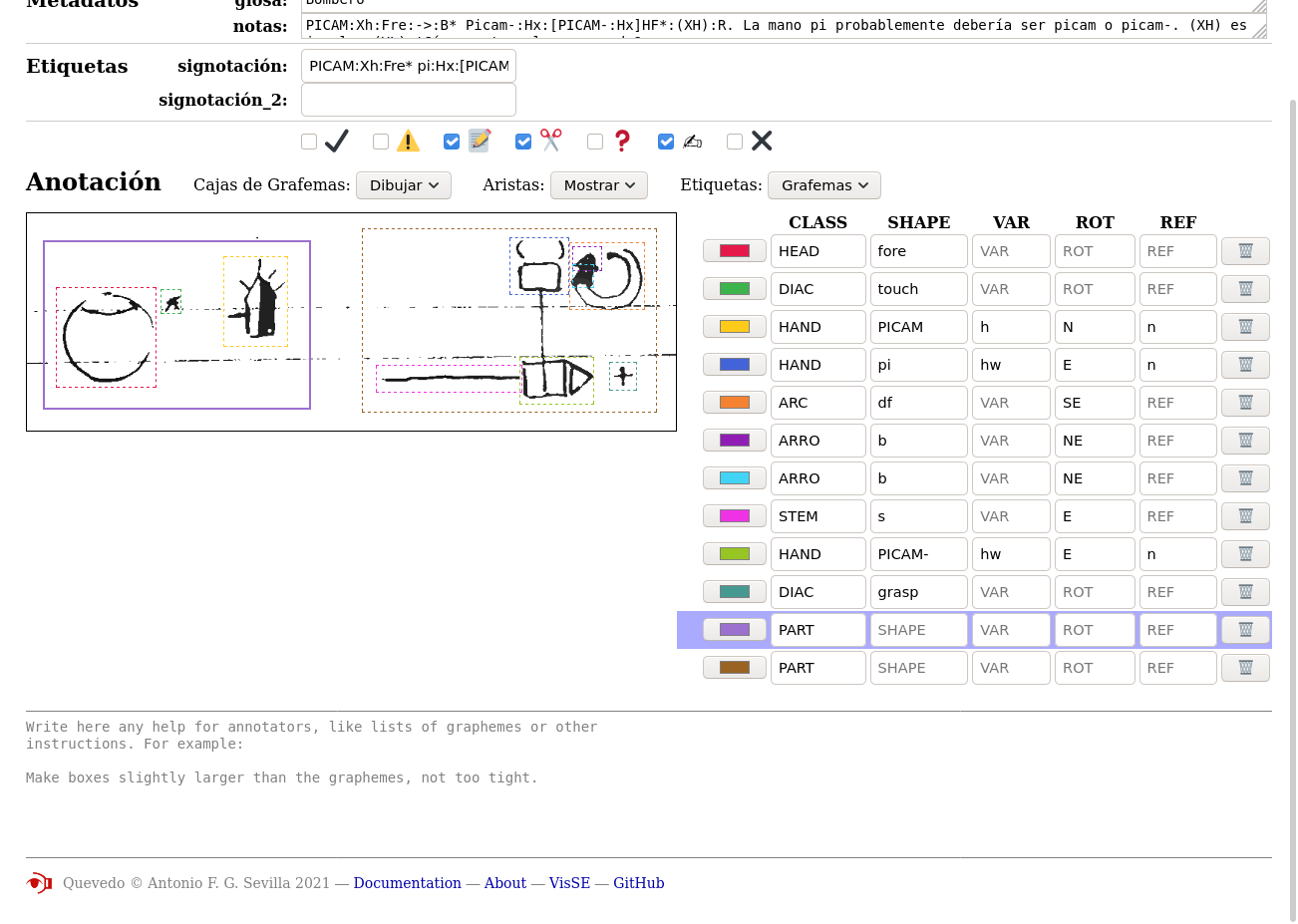
El uso de Quevedo como infraestructura, codificando de manera formal y automática todos los procesos, fue una ayuda constante en la anotación, ya fuera realizando chequeos o correcciones deterministas que podían ser ejecutadas por la máquina, o efectuando una pre-anotación automática que posteriormente era revisada y corregida por el humano. Este proceso, conocido como bootstrapping, es una técnica habitual en el estado del arte, y se basa en el uso de resultados preliminares de los algoritmos de aprendizaje automático para agilizar el proceso de anotación. Primero, los humanos anotan manualmente y con detalle un subconjunto de datos. Este subconjunto se emplea luego para entrenar los algoritmos, que, aunque no alcanzan una gran precisión, ofrecen ya una anotación preliminar que puede ser corregida por el humano. Con estos nuevos datos anotados y corregidos, se vuelve a entrenar el algoritmo, resultando ahora en una mejor aproximación, por lo que la corrección manual se agiliza. Esto acelera la anotación, al tiempo que permite comprobar que los algoritmos están funcionando correctamente, y realizar las mejoras y adaptaciones que se observen necesarias sobre la marcha.
En la siguiente sección, abordaremos estos algoritmos en detalle, pero la herramienta Quevedo se describe con más profundidad en la sección 3.5.1 y los capítulos 9 y 10. Como ya se ha mencionado, los datos anotados han sido publicados en línea en Zenodo (Sevilla, Lahoz-Bengoechea, y Díaz 2022), junto con la guía de anotación en español e inglés y reproducida en el capítulo 7. El artículo “Building the VisSE corpus of Spanish SignWriting”, reproducido en el capítulo 6 y aceptado para publicación en la revista Language Resources and Evaluation, amplía lo expuesto en esta sección y ofrece algunas estadísticas preliminares sobre el corpus.
Al estar Quevedo disponible libremente en el repositorio de paquetes de Python (PyPI), cualquier usuario puede examinar visualmente el corpus con los comandos de terminal enunciados en el listado de código 3.1.
$ wget https://zenodo.org/record/6337885/
files/visse-corpus-2.0.0.tgz?download=1
$ tar xzf visse-corpus-2.0.0.tgz
$ cd visse-corpus
$ pip install quevedo[web]
$ quevedo web